



The New Laws of Intelligence: A Manifesto for the AGI Age
In the wake of o3, a look at how scaling, complexity, and human inertia are reshaping the future—from token streams to fractal software to our own future in this new world. Part of a series, probably.

If it feels like we’re dancing on the edge of a tech singularity, it’s because we kinda are. There’s a swirling mix of breakthroughs, misunderstandings, cultural inertia, and serious moral dilemmas—all hitting at once. Below is an attempt to decode the “new laws” shaping our intelligence-driven future, arranged in an order that hopefully flows like a good narrative. Let’s roll up our sleeves and dive in.
If you’ve been paying attention, you’ve heard about o3 by now. It’s not just about building bigger neural nets and feeding them more data anymore. It is the #175 best programmer in the world. It is breaking the ARC-AGI prize. It is smarter than 99.99999% of humans at math (25% on FrontierMath is a big deal). Yes I counted the 9’s and that does leave ~800 of us who are better at math than o3 which tbh might be generous.

So what does this all mean for us? First, I do believe something has fundamentally shifted in the last year. In the last quarter. You can’t look at this graph of AGI performance by AI and not think so.
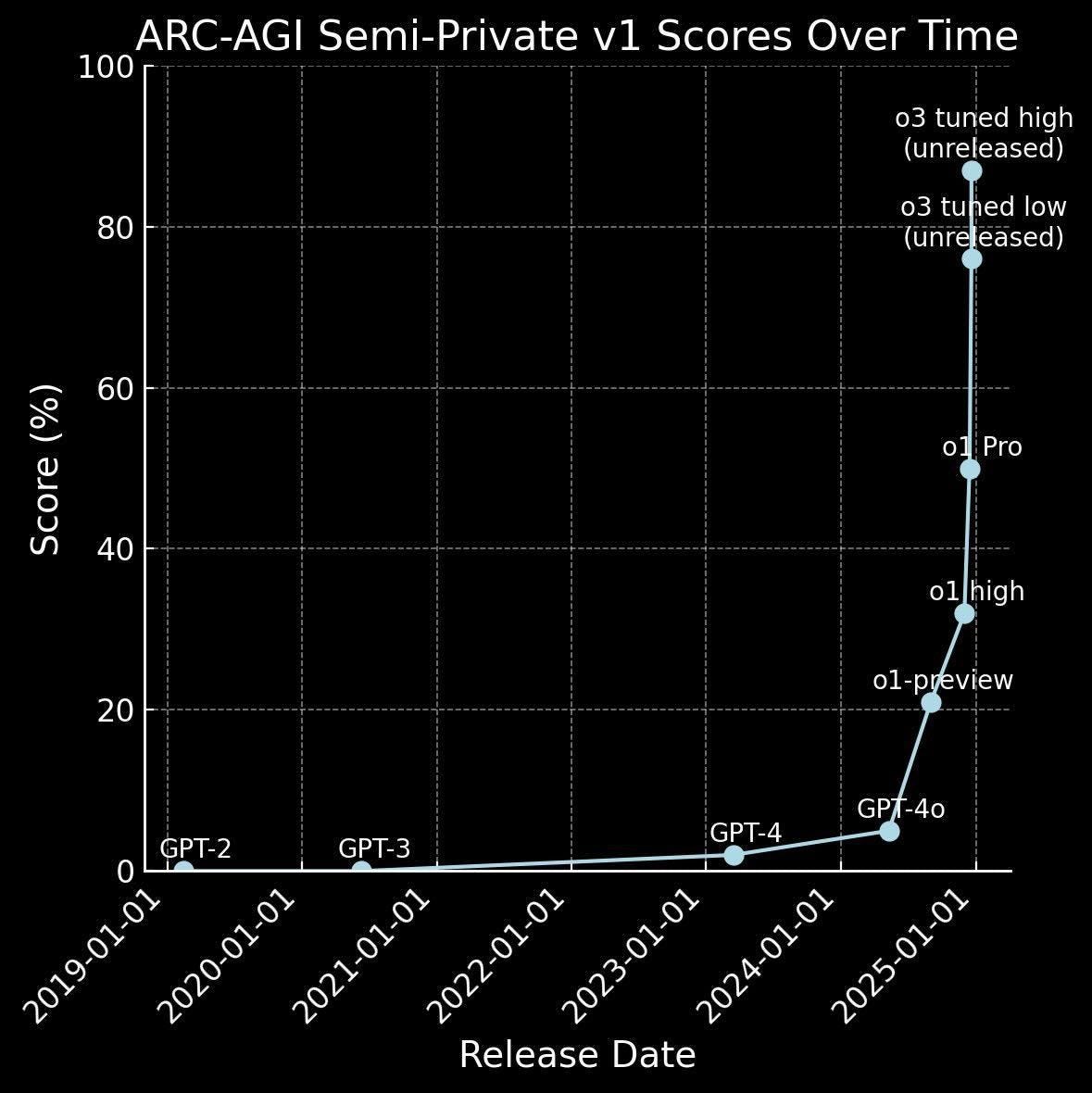
Take a minute to digest that graph. Once you have, I’d like to suggest a series of increasingly spicy takes on what will characterize the new intelligence age we’re entering. Let’s start with the baseline assumption that the world as we know it will be fundamentally different, and instead of predicting future events it’s probably more useful to infer scaling parameters. I call these laws for short, but think of them more like an attempt to infer or discover dynamics that should drive social and technical systems in a world where intelligence is going vertical.
So here’s my take on 13 laws that I think will start to get sharp next year.
1. Intelligence scaling laws are abundant, not scarce
I said this would be in increased order of spiciness but as I write this I realize this one is already pretty spicy. Does anyone remember when just a month or so ago this was revolutionary? The idea that test time compute could add a second scaling law suggested that we were going to rapidly increase intelligence going forward (see graph above).

But what if I were to tell you that we’re starting to see signs of yet a third scaling law?Credit to Shengjia Zhao for calling this out:
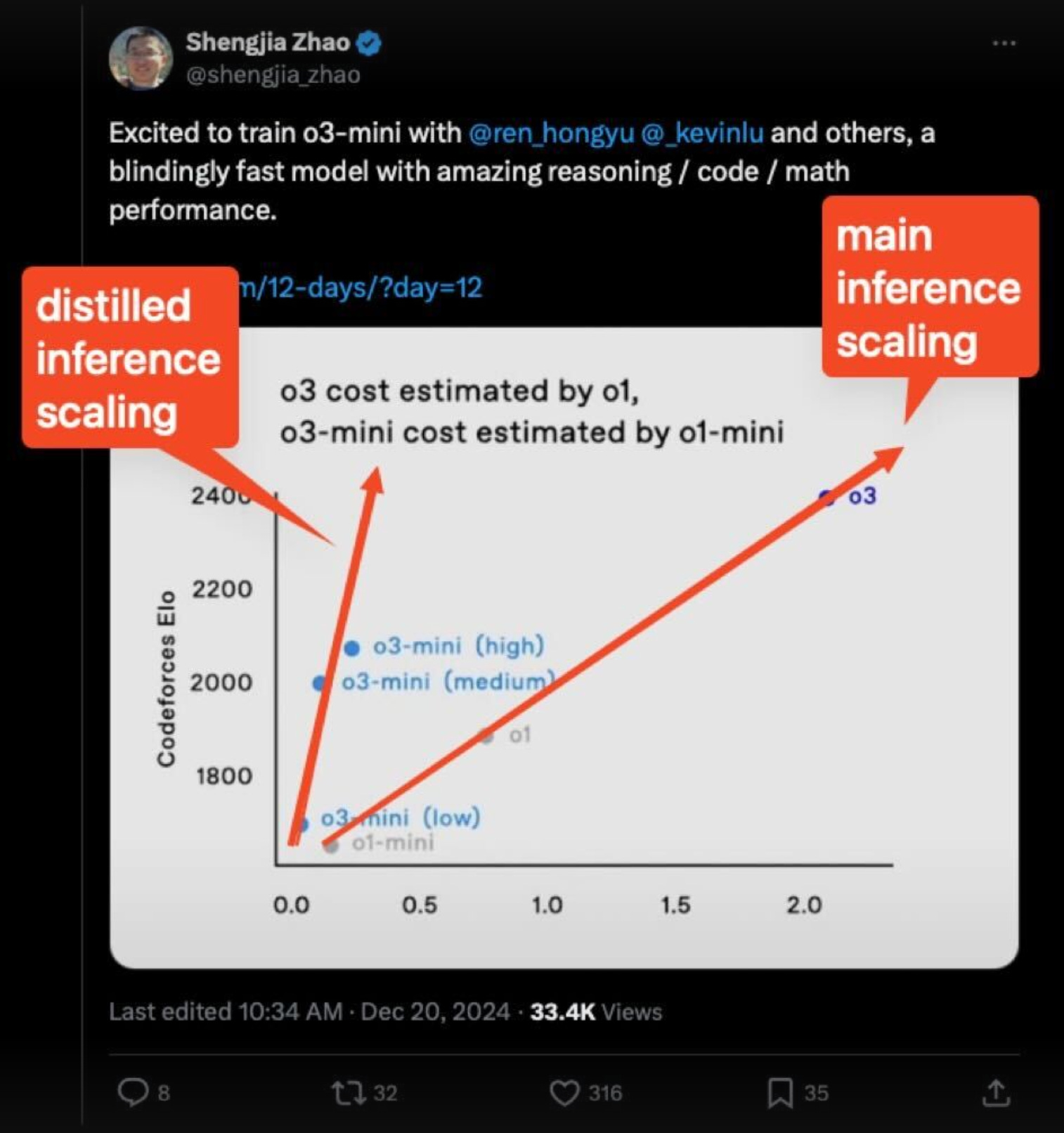
The implication here is profound. If there is indeed another scaling law around distilled inference scaling, it suggests that distilled inference models (minis) will become cheaper more quickly as main inference models scale in intelligence. This lines up well with OpenAI’s confidence that they can release a scaled down o3 mini that is performant and cheap quickly. A distilled inference scaling curve is a massive driver of intelligence ubiquity—it implies a future where extremely expensive e edge performance is followed quickly by Pareto principle mini versions that capture most of the value at a several orders of magnitude less cost. If your new intelligence model is 5x better and you can deliver 80% of that at 1% of the cost of the original quickly then intelligence is going to get faster and cheaper than most of us are able to imagine.
2. But We’re Already (for Practical Purposes) Over-Abundant
Here’s the kicker: in many ways, we already have more intelligence than we strictly know what to do with. While the media fixates on the next big GPT release, we’re actually underutilizing the AI that’s right under our noses. Even a run-of-the-mill large language model can handle an absurd swath of tasks—ranging from summarizing legal documents to drafting marketing copy to analyzing bug logs. It’s an ocean of capability, waiting.
But we have organizational gridlock, confusion over best practices, and a general “Wait, is it safe to trust AI with that?” mindset. To be fair to most of us, the main model makers have been so busy building models that they haven’t really socialized the capability set these models bring to the table, nor have they had time to actually evaluate model capabilities in real-world scenarios across multiple industries. This leads to a core insight: most model capability in your industry is undiscovered, and the undiscovered territory there is increasing exponentially as models gain intelligence faster and faster. So the real bottleneck isn’t some imaginary shortage of smarts; it’s our (very human) inability to integrate these powerful tools into daily life. That’s a theme you’ll see repeated: plenty of intelligence, not nearly enough social, legal, or infrastructural readiness.
3. Problem Complexity Has Incremental Cost
Now, for a twist: While we bask in that ocean of intelligence for the everyday stuff, the edges of AI are a different story. Going from “really good” to “holy crap, near-human or above-human” intelligence can get astronomically expensive. We’re talking exponential jumps in compute power, specialized engineering, huge data pipelines—just to inch forward another few percent in performance. I’m not actually making that up—during ARC-AGI evals o3 cranked up delivered an incremental 3.5 percentage points in score gains per hour of compute across a 16 hour test.
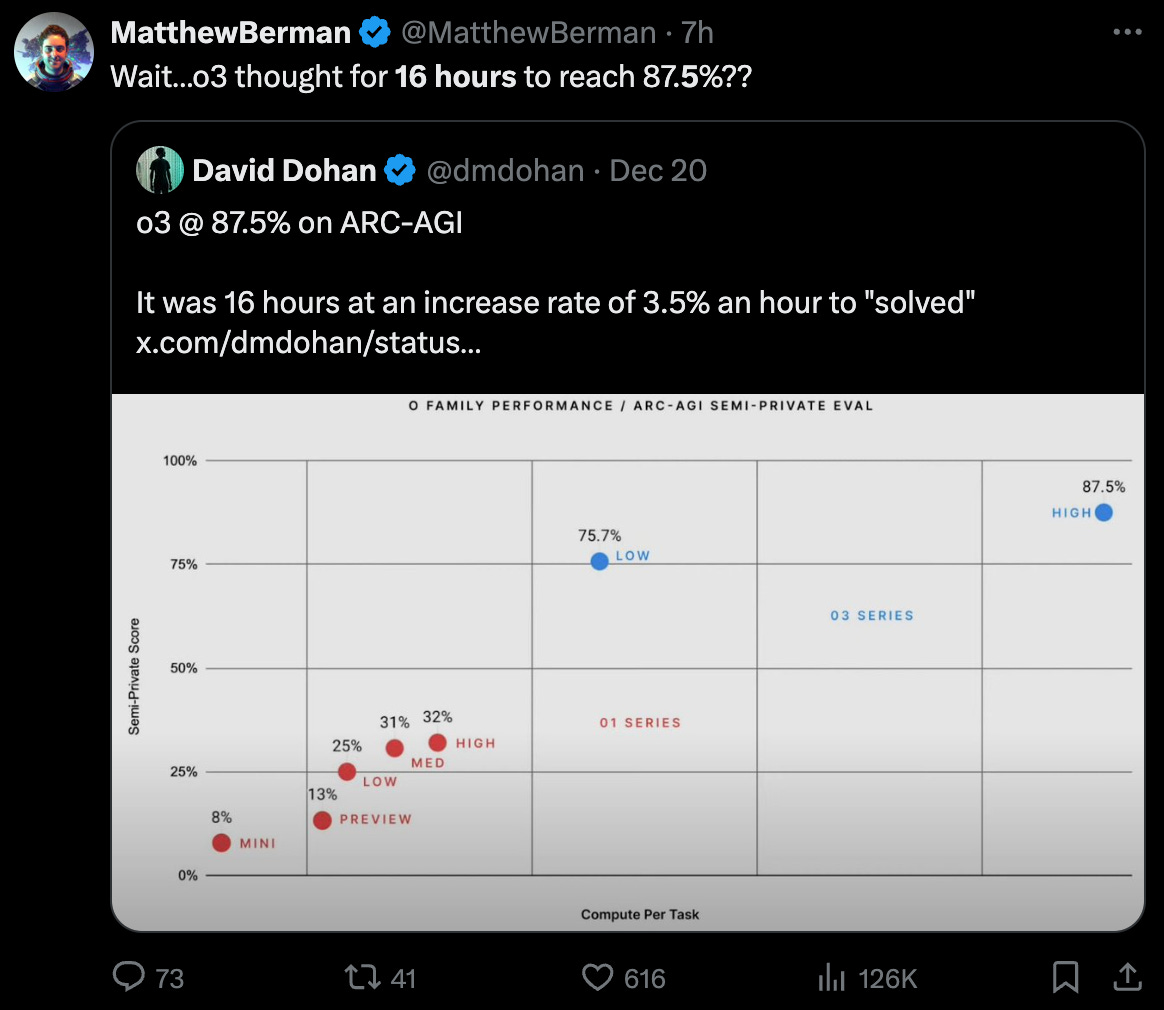
So is it worth it? In niche, high-stakes domains—drug discovery, fusion energy modeling, nuclear deterrence simulations—absolutely. But for the majority of tasks, the ROI of the maximum intelligence we already have becomes questionable. This is why o1 Pro (we hardly knew ye) was targeted to science and researchers.
This is a big deal, because it sort of breaks our brains. We’ve lived in a world of flat intelligence for all of species history. Now we live in a world of exponential intelligence. In our previous world tool use was a breakthrough technology. Now leverage may be shifting elsewhere in the intelligence landscape. For instance, ability to correctly map complexity to model may become a highly monetizable skill. We can’t just say, “Sure, 10x the compute budget, we want 1% more accuracy” unless we really need to move from 98% to 99% on a task. The cost curve is no joke.
And this brings me to…
Keep reading with a 7-day free trial
Subscribe to Nate’s Substack to keep reading this post and get 7 days of free access to the full post archives.